Raspberry Pi
(3)Google音声認識(Speech API)を使ってみる
Google音声認識APIを使う。
次のように設定しました
・Raspberry Pi2に「jtalk」と「WiringPi」をインストール。設定は省略します。
本ホームページの「Raspberry Piを使って、音声命令でキャタピラを操作」を参照してください。
・Google からSpeech API key を取得。
・Google音声認識API を使って、雑談対話を試す。
・雑談対話の返事を「jtalk」の「メイちゃん」の声で応答させる。
Google音声認識(Speech API)について
1.NTTDocomoの音声認識APIは、以下の2通りがあります。
(1)「Powered by NTTテクノクロス」・・・Androidで提供
(2)「Powered by アドバンスト・メディア」・・・REST形式で提供
前回の「OpenJtalkと+NTTdocomo音声認識・雑談会話APIをつかって会話を楽しむ(2)」
では②の音声認識「Powered by アドバンスト・メディア」を使って雑談対話を試してみましたが、
APIキーは利用期間が90日間の制限があります。
そこで、Googleの音声認識API「Speech API」を使って、NTTdocomo雑談会話を試みてみたいと
思います。
2.Googleの音声認識API「Speech API」の使用料金及び音声エンコードは次のようになっています。
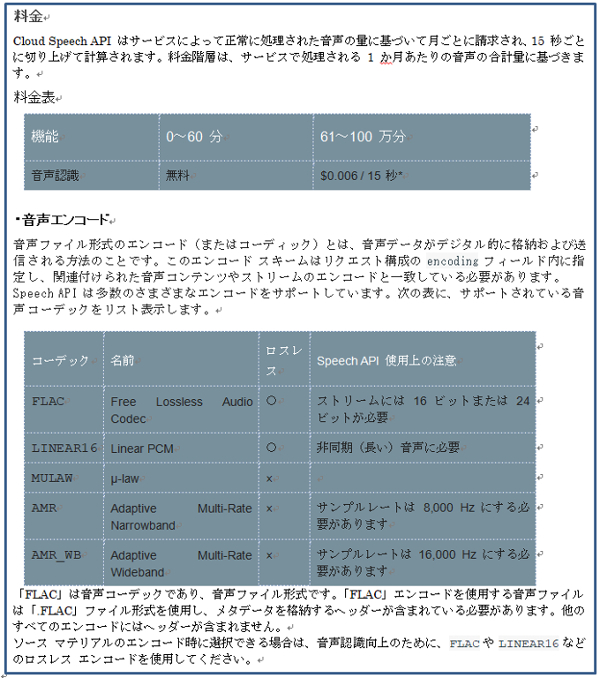
前回の「OpenJtalkと+NTTdocomo音声認識・雑談会話APIをつかって会話を楽しむ(2)」では、
「.wave」ファイル形式を使っていましたので、
今回、音声ファイルは「.FLAC」ファイル形式を使用し、メタデータを格納するヘッダーが
含まれている必要があります。
そこで書籍「自然会話ロボットを作ろう!」を参考させてもらい、音声処理ライブラリ「sox」を
使うことにしました。
事前のソフト及びアンプの回路等は、前のページ「(2)Pythonプログラムを作成し雑談対話を試す」
と同じです。
soxライブラリを使う
1.soxライブラリをRaspberry Piにインストール。
ターミナルで次のように入力しインストールします。
$ sudo apt-get install alsa-utils sox libsox-fmt-all
2.音声入出力のカード番号等については、他のページ「Raspberry Piを使って、音声命令で
キャタピラを操作(1)」と同様ですので参照してください。
再掲しますと、
(1)音声入力カード番号は、ターミナルで、「 $ arecord -l 」と入力し確認します。
(2)音声出力のカード番号は、同様にターミナルで、「 $ aplay -l 」と入力し
確認します。
3.音声入力のテスト
(1)ターミナルで次のように入力し、5秒以内でマイクロフォンに向かって話して音声入力の
テストをします。
$ AUDIODEV=hw:1 rec -c 1 -r 11025 speak.flac trim 0 5
・AUDIODEV=hw:1 は、音声入力デバイスで、カード番号が1。
・-c は、音声チャンネル数で、1はモノラル。
・-r は、サンプリングレートで、11025は11025Hz。
・speak.flac は、出力先の音声データファイル。
・trim は、音声入力時間で、0 5は、入力時間が5秒。
(2)音声入力データの確認
ターミナルで次のように入力して、録音したデータを再生し、スピーカーから
聞こえたらOKです。
$ play speak . flac
音声入力の確認プログラム 「listen . py」を作成
音声入力の確認プログラム「listen . py」を作成し、Google Speech APIを確認します。
1.「listen . py」のプログラムは、次のようにしました。
# python listen.py #!/usr/bin/env python # -*- coding: utf-8 -*-
import sys import os import time import requests import json PATH = '/home/pi/speak.flac' GOOGLE_APIKEY = 'Google Speech-APIキー' url_v ='https://www.google.com/speech-api/v2/recognize?xjerr=1&client=chromium&lang=ja-JP& maxresults=10&pfilter;=0&xjerr=1&key=' + GOOGLE_APIKEY hds = {'Content-type': 'audio/x-flac; rate=11025'} os.system("gpio -g mode 7 out") def recognize(): files = open(PATH, 'rb') voice = files.read() files.close() try: rsp = requests.post(url_v, data=voice, headers=hds).text except IOError: return '#CONN_ERR' except: return '#ERROR' objs = rsp.split(os.linesep) for obj in objs: if not obj: continue alternatives = json.loads(obj)['result'] if len(alternatives) == 0: continue return alternatives[0]['alternative'][0]['transcript'] return '' os.system("/home/pi/jtalk.sh 会話を始めます") while True: os.system("gpio -g write 7 1") os.system("AUDIODEV=hw:1 rec -c 1 -r 11025 " + PATH + " trim 0 5") os.system("gpio -g write 7 0") message = recognize().encode('utf-8') if (message == '#CONN_ERR'): print 'internet not available' message = '' elif (message == '#ERROR'): print 'voice recognizing failed' message = '' else:
print 'your word:' + message if message == "": print "クライアントの実行を停止します" os.system("/home/pi/jtalk.sh 会話を終了します") break
2.動作は、次のようになります。
(1)起動後、「メイちゃん」の声で、スピーカーから「会話を始めます」と聞こえます。
(2)それと同時に、アンプに設置している青のLEDが点灯します。青のLEDが点灯したら
マイクに向かって話します。
(3)青のLEDが消灯したら音声入力は終了です。5秒間の間に話します。
(4)画面に話した内容が表示されます。
(5)再度、青のLEDが点灯しますので、マイクに向かって話します。これの繰返しです。
(6)青のLEDが点灯しているときに、何も話さない(無音)と、画面に「クライアントの
実行を停止します」と表示され、
「メイちゃん」の声で、スピーカーから「会話を終了します」と聞こえます。
そしてプログラムは、break します。
3.「listen . py」を実行した結果が次の画面です。(Python2 IDEを使用)
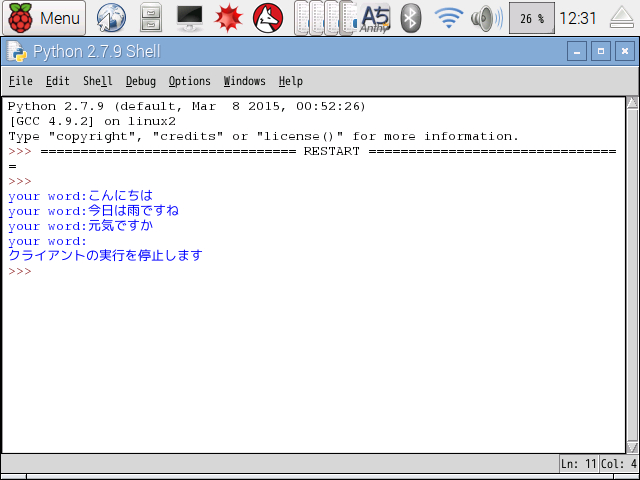
Google Speech APIが何とか動いています。
プログラム中の「jtalk.sh」は、シェルスクリプトで、他のページ「Raspberry Piを使って、
音声命令でキャタピラを操作(1)」に記していますので確認してください。
Google音声認識APIを使って、雑談会話を試みる。
Google-Speech-APIを使って、雑談会話を試みる
1.雑談会話のプログラム「zatudan.py」は次のようにしました。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
import os
import time
import requests
import json
PATH = '/home/pi/speak.flac'
DOCOMO_APIKEY= 'NTTDocomo-雑談対話APIキー'
GOOGLE_APIKEY = 'Google Speech-APIキー'
url_z = 'https://api.apigw.smt.docomo.ne.jp/dialogue/v1/dialogue?APIKEY=%s'%(DOCOMO_APIKEY)
url_v ='https://www.google.com/speech-api/v2/recognize?xjerr=1&client=chromium&lang=ja-JP&
maxresults=10&pfilter=0&xjerr=1&key=' + GOOGLE_APIKEY
hds = {'Content-type': 'audio/x-flac; rate=11025'}
modeID = ""
contextID = ""
os.system("gpio -g mode 7 out")
def recognize():
files = open(PATH, 'rb')
voice = files.read()
files.close()
try:
rsp = requests.post(url_v, data=voice, headers=hds).text
except IOError:
return '#CONN_ERR'
except:
return '#ERROR'
objs = rsp.split(os.linesep)
for obj in objs:
if not obj:
continue
alternatives = json.loads(obj)['result']
if len(alternatives) == 0:
continue
return alternatives[0]['alternative'][0]['transcript']
return ''
def dialogue(message):
global contextID, modeID
userload = {
"utt": message,
"context":contextID,
"nickname": "椋",
"nickname_y": "ムク",
"sex": "男",
"bloodtype": "A",
"birthdateY": "1997",
"birthdateM": "1",
"birthdateD": "16",
"age": "30",
"constellations": "水瓶座",
"place": "横浜",
"mode": modeID,
"t": ""
}
r = requests.post(url_z, data=json.dumps(userload))
print ("Mei: "),
print r.json()['utt']
modeID = r.json()['mode']
contextID = r.json()['context']
return r.json()['utt']
os.system("/home/pi/jtalk.sh 会話を始めます")
while True:
os.system("gpio -g write 7 1")
os.system("AUDIODEV=hw:1 rec -c 1 -r 11025 " + PATH + " trim 0 5")
os.system("gpio -g write 7 0")
message = recognize().encode('utf-8')
if (message == '#CONN_ERR'):
print 'internet not available'
message = ''
elif (message == '#ERROR'):
print 'voice recognizing failed'
message = ''
else:
print 'your word:' + message
if message == "":
print "クライアントの実行を停止します"
os.system("/home/pi/jtalk.sh 会話を終了します")
break
talkmessage = dialogue(message)
os.system("/home/pi/jtalk.sh " + talkmessage.encode('utf-8'))
time.sleep(5)
2.雑談会話のプログラム「zatudan.py」の実行結果は次の通りになります。
(Python2 IDEを使用)
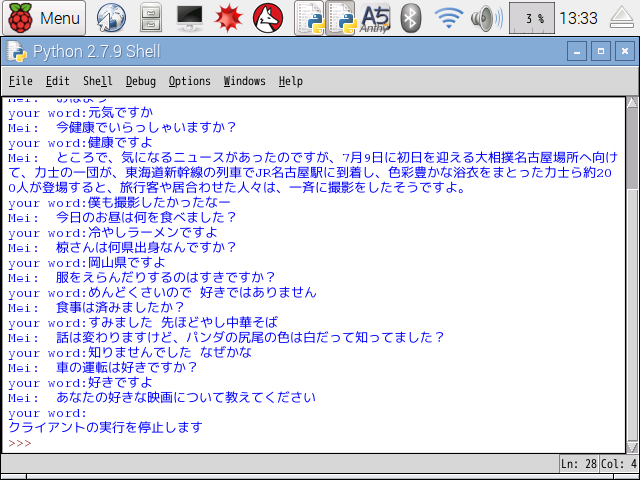
画面だけでなくスピーカーから「Meiちゃん」の声で応答があります。
雑談対話は、こちらが質問すると話が飛んでしまい、そのうち質問ばかりに
なってきて、こちらが答える形になってしまいます。
しかたないのかな?